The Frontend Workflow for AI
How humans and agents build together without breaking prod





By Chromatic Editorial
Senior technical staff













Who we researched for this guide
Frontend development runs on a feedback loop: you build a component, test it, review the change, and ship. AI accelerates that loop, generating components in seconds… and often introducing slop.
To bring AI into frontend workflows, humans and agents need to share the same loop. Each covers the other's blind spots: AI brings speed, humans bring judgment.
This guide shows how teams combine human and AI effort to move faster without breaking things. We'll cover how to structure your workflow and measure it.
Who is this for
For frontend teams shipping production components at scale. You already have CI, testing, and review workflows and want to safely add AI to improve quality and speed.
Skip if you're still searching for product-market fit or shipping infrequently. Early teams move faster by testing ideas, not infrastructure.
Why trust us?
We researched dozens of teams: Priceline, Spotify, Dayforce, Monday.com, MongoDB, Wise, and more. That includes surveys, live sessions, and workflow audits. We build Storybook, used by half of the Fortune 50. That reach gives us visibility into best and worst practices.
The current state of AI coding
"AI" gets thrown around to mean everything from code autocomplete to full-stack agents. So before we begin, let's get our terms straight:
- AI: the broad capability that enables code generation.
- Agents: actors that apply AI capabilities, stand-ins for developers.
- LLM: underlying model that consumes tokens and does inference.
- MCP (Model Context Protocol): protocol that feeds agents validated context and supplies tools
Together, these form the current toolchain for AI-assisted development: agents perform work, LLMs power them, and MCP supplies context so their output reflects reality.
AI speeds up the feedback loop
Frontend developers build systems of components that must behave predictably. That process follows a loop with two steps:
- Build: Create or update components that capture every relevant state.
- Test: Run functional, visual, and accessibility checks to confirm behavior.
The best teams use agents for specific tasks that benefit from repetition. They still rely on humans in the loop to define intent, review results, and make judgment calls. The diagram below shows where agents fit:
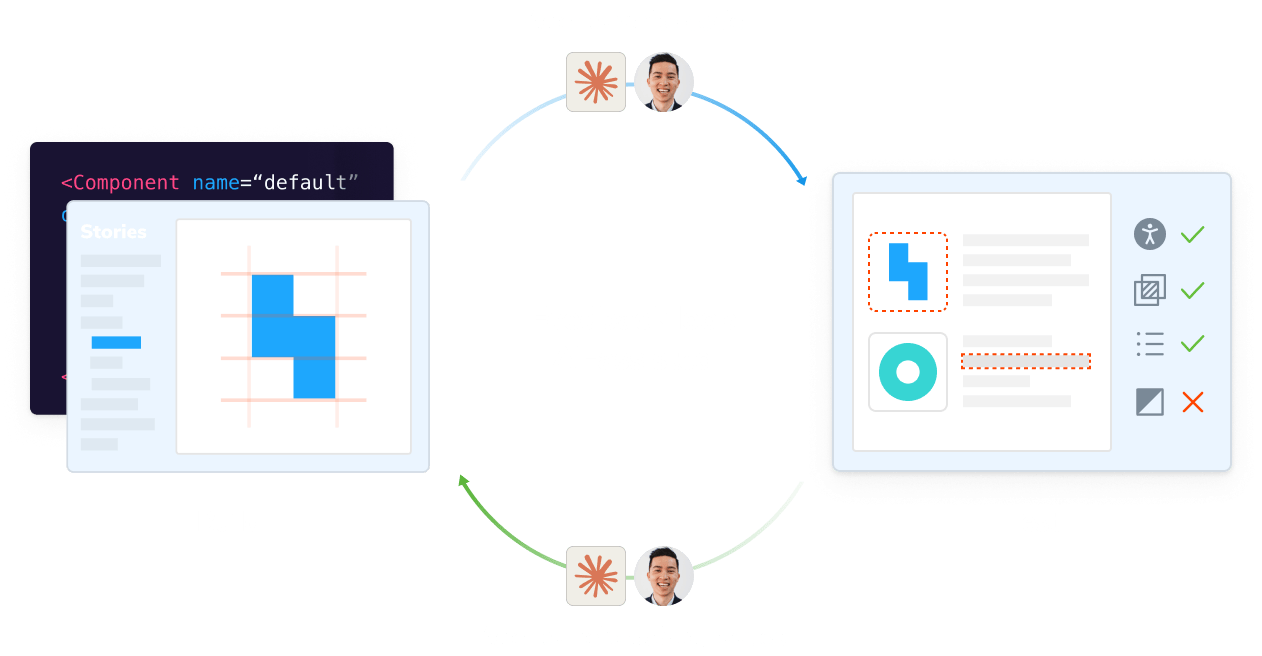
No single tool or agent spans the full frontend loop. Each covers a piece of the workflow: code generation, testing, review, or deployment. Developers compose these capabilities to suit their own working style (CLI, IDE, chat interface) and toolchain (CI, web host, observability). It's the frontend team's job to assemble a unified workflow where context and results flow seamlessly between steps.
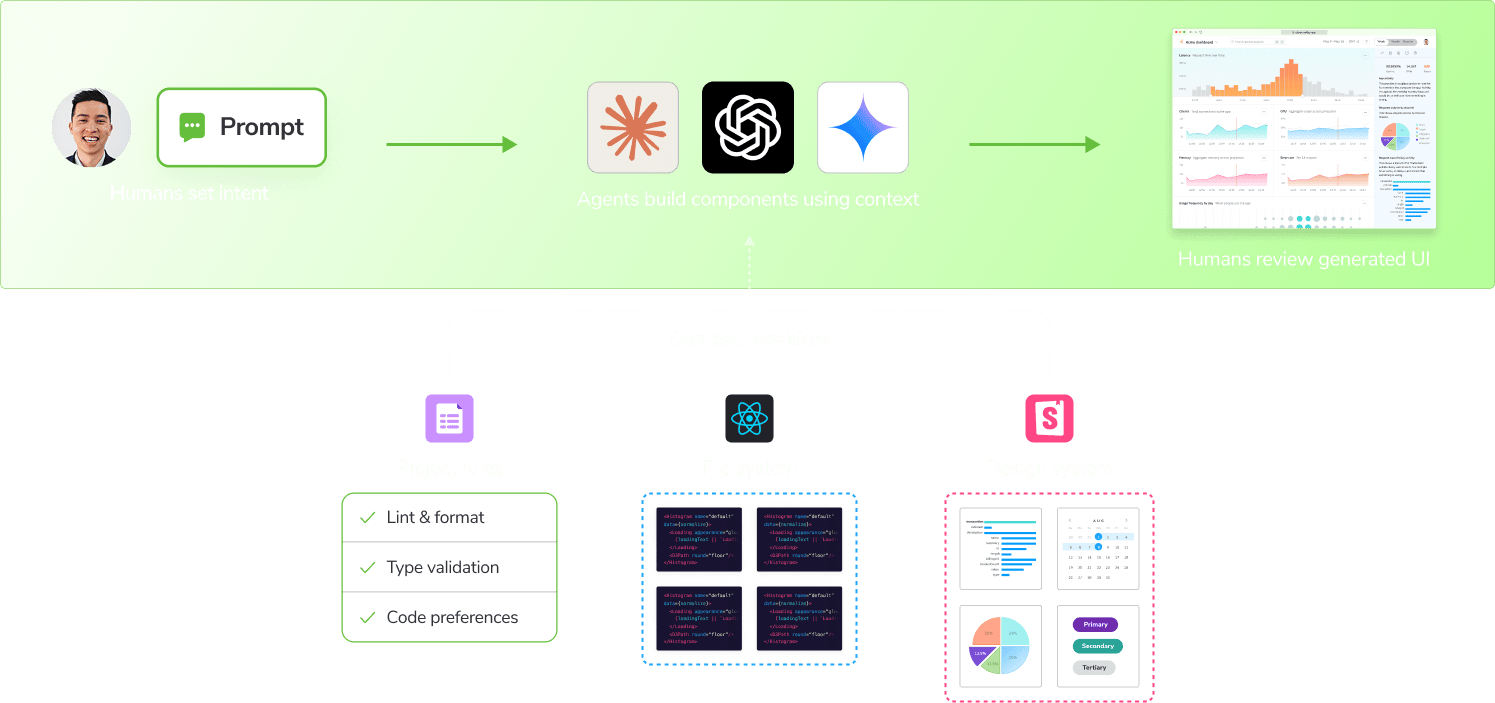
1. Build faster by giving agents the right context
Agents can generate streams of code, write stories, and wire up types. But teams only merge code that conforms to the existing system: your components, props, naming, and architectural patterns.
Conformance depends on context. Agents need to understand how components behave and how they're meant to be used. With validated stories, metadata, and prop definitions, they build within your system instead of inventing new patterns. Chromatic surfaces this metadata as UI context for agents.
| Benefit of AI | How it works | Outcome |
|---|---|---|
| Scaffold code | Agents speed up repetitive work like linting, writing stories, and type checking. Developers are responsible for setting intent and confirming results. | Repetitive work moves to AI while developers focus on planning and review. |
| Reuse components | Agents reuse existing production-ready components instead of inventing new ones or hallucinating. | Code aligns with what's already shipped, cutting review time and avoiding pattern drift. |
The result is speed without losing craftsmanship. Agents handle mechanical work while developers focus on flows that define the product. Faster, conformant output raises a new problem: you have more code to validate and review.
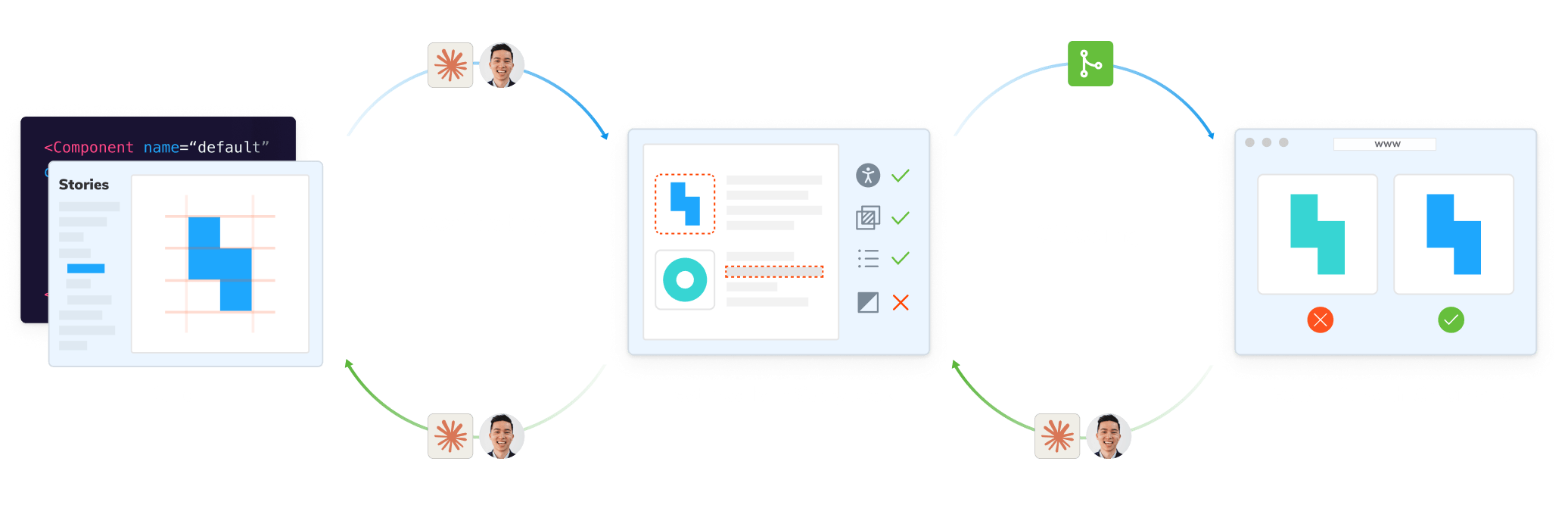
2. Invest in tests as guardrails for agents
Tests are the only thing standing between you and software entropy. You already use stories, tests, and baselines to show what's possible and what's "good."
With agents, those same guardrails become even more critical. Tests inject feedback - errors, warnings, and logs - into an agent's internal loop without humans needing to intervene.
A test suite validates your frontend with visual, functional, and accessible checks. Run those checks across states, browsers, and environments, and you prevent a vast matrix of potential regressions.
Here's how to divide the testing work between humans and agents:
| Who | Handles what | Outcome |
|---|---|---|
| Agents | Resolve deterministic issues such as prop mismatches, missing types, and accessibility violations. | Continuous, low-cost feedback. |
| Humans | Review ambiguous visual diffs, UX intent, and breaking API changes that require judgment. | Reliable decisions that maintain intent and design standards. |
That split maps to two testing loops you currently run.
- Local testing runs on a developer's machine to catch obvious issues. The scope is intentionally narrow to speed up feedback before committing code.
- Agents self-heal deterministic issues, iterating with tests until they pass.
- CI testing runs in the cloud for certainty before merge. It covers every combination of test type, state, browser, and environment.
- Agents commit fixes directly in pull requests, closing the loop across the entire system.
Chromatic provides the tooling that humans + agents use to test locally (Storybook) and in CI. The result is continuous validation that scales for AI workloads while still meeting human standards for quality.
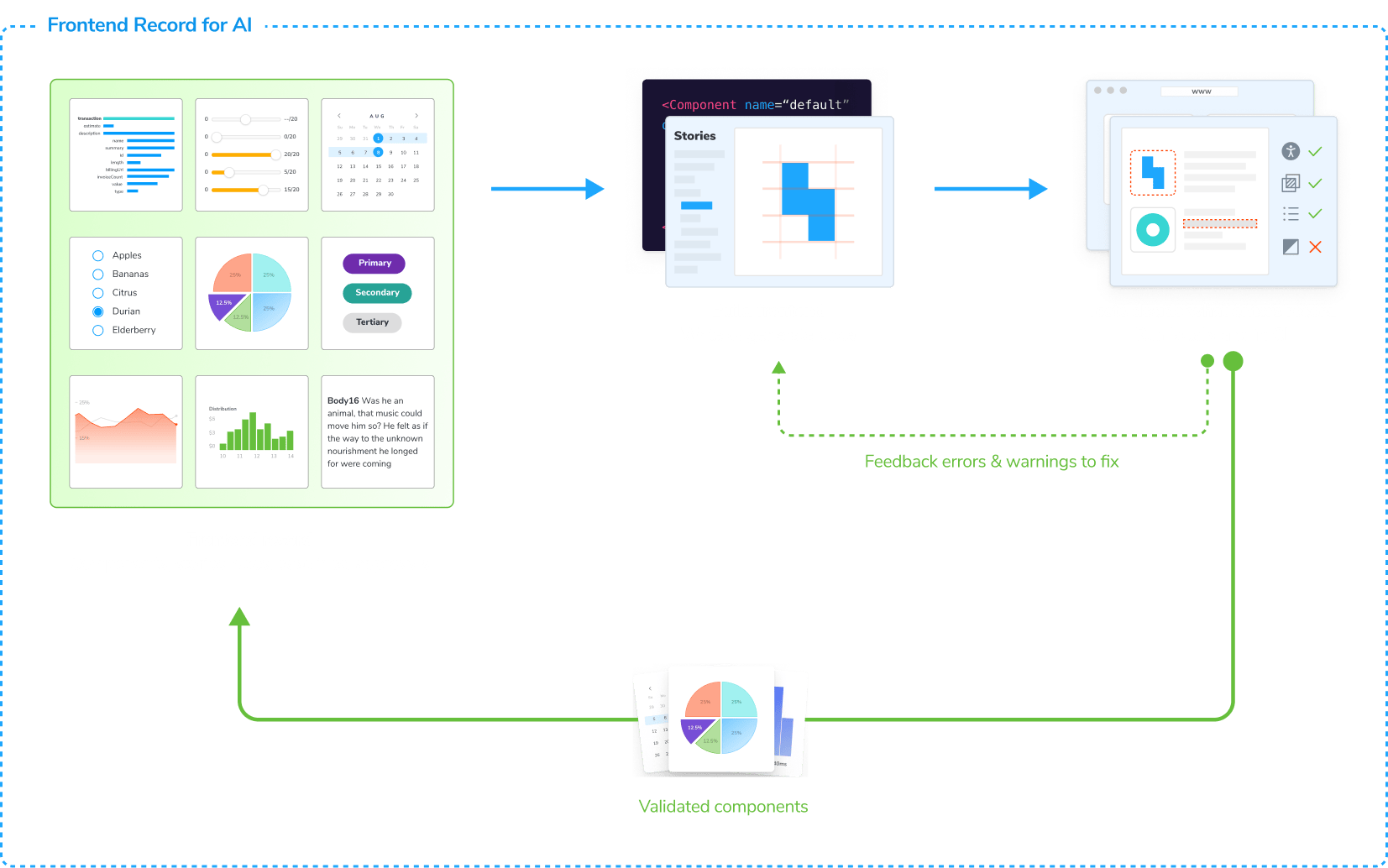
AI requires a frontend record
Zoom out. With AI, your team's responsibility shifts from coding components to creating a system where humans and agents work together.
Stories, metadata, and tests define how your UI behaves and what counts as correct. Together they form a living frontend record that evolves continuously through CI.
You maintain the frontend record by tracking changes, validating quality, and curating what enters the record. Agents draw from this validated context via MCP when generating code. And their code is governed by the same workflow.
Split responsibilities between humans, agents, and services
Once the system of record exists, both humans and agents operate within it. They share the same test signals, review cycles, and approval paths. Agents automate repetitive tasks; humans decide what meets intent. Chromatic connects those roles into a single feedback loop.
| Role | Responsibilities | Responds to |
|---|---|---|
| Agents | Generate/refactor/fix components, run local tests, propose commits with diffs. | Deterministic signals: test pass/fail, schema violations, missing coverage. |
| Humans | Define intent, review diffs, approve baselines, resolve ambiguous results. | Signals that require judgment: visual shifts, UX intent, breaking API changes. |
| Service (Chromatic) | Evaluates test results, governs what enters the record, then generates context for LLMs. | Humans approving new and changed components to enter the record and get served as context. |
Measure that your system actually works
Every internal AI initiative promises the same thing: faster delivery and lower cost. Yet many teams don't see that hype materialize. You may have replaced coding with prompting, but none of that matters if velocity, quality, and cost didn't improve.
Measurement is how you prove your system saves time and money instead of just shifting effort around. Track four signals to understand performance over time: UI context coverage, success rate, time to prompt completion, and token usage.
UI context coverage: % test coverage × % schema integrity
UI context coverage measures how much of your frontend system is available to agents as validated context. Higher coverage means agents can reliably reuse existing components, states, and patterns instead of inventing new ones.
Success rate: % tests passing
Success Rate captures how often generated components pass your evaluation suite. The suite uses a fixed set of representative prompts, run repeatedly over time, to measure whether AI output conforms to your UI standards.
Time to prompt completion: prompt duration
Time to Prompt Completion tracks how quickly a prompt turns into code ready for review. This measures how long developers wait between iterations while agents do their work.
Token usage: tokens
Token Usage measures how many tokens the system consumes to reach a passing result. It reflects how efficiently context is applied during code generation.
Tune the system
Run the same prompt 100 times and you'll get 100 different UIs. These effects compound when AI is embedded into a frontend workflow.
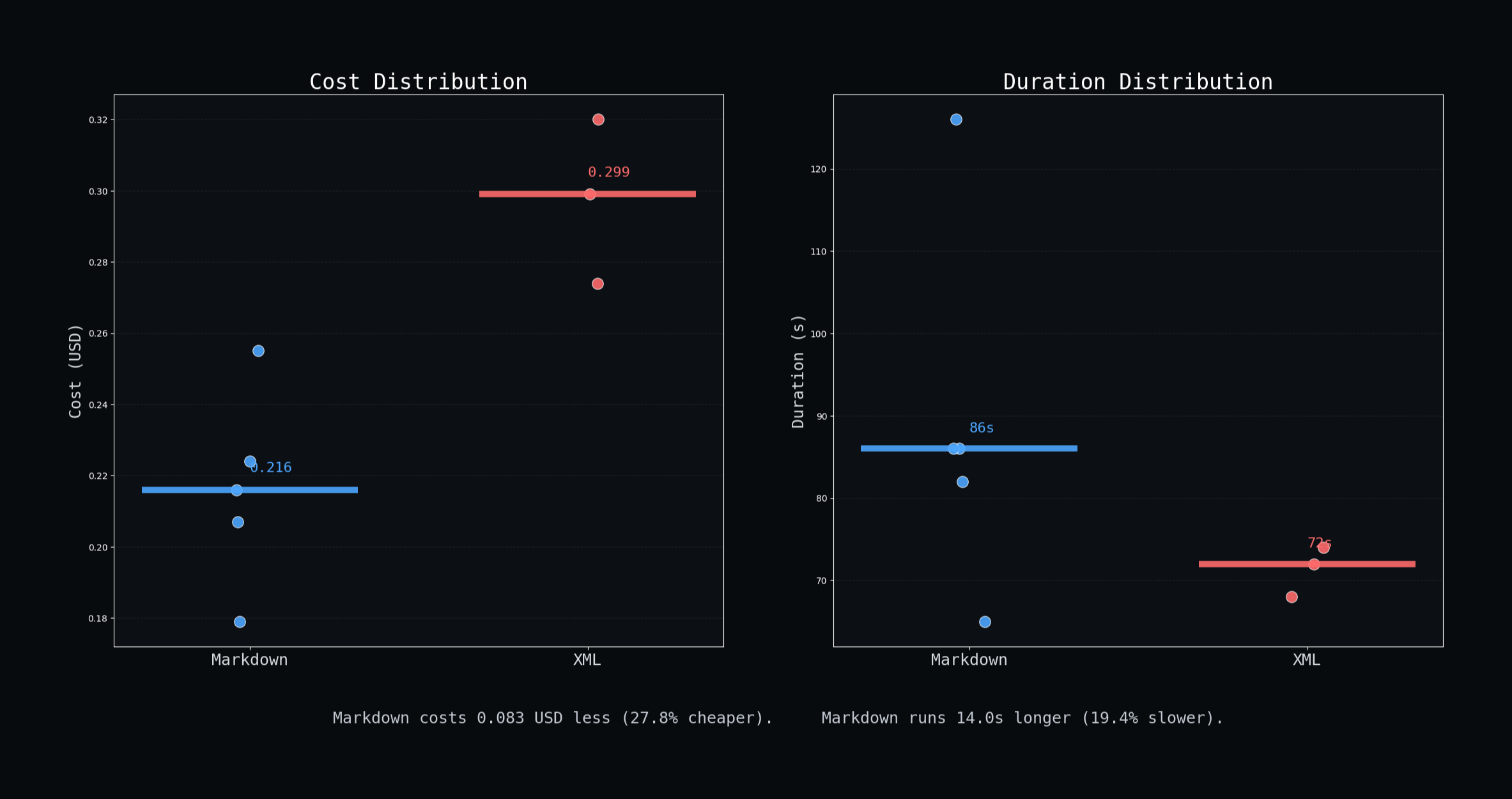
We benchmarked dozens of projects and found the adage "quality, speed, cost—pick two" still applies in the AI era.
In order for you to deploy AI successfully, measure how your system behaves over time. Metrics on success rate, time to prompt completion, and token usage form distributions. Examine their spread and clustering to tune performance and detect regressions.
Where to start
You've probably done the hard part already. The average team has a feedback loop: components that describe behavior, tests that prove it, and CI that keeps the cycle running. This guide shows where to extend that loop so agents can work inside it:
- Provide UI Context
- Use tests as guardrails
- Measure with evals
It's OK to start small. Add agents where repetition slows you down. Generate stories from real states. Approve what passes and let Chromatic keep the record. Over time, the agentic loop will become the backbone of frontend delivery, with every change validated before it ships.